I think the “spine” described here makes a really good point:
[REDACTED]
~ from private communication
It’s a shame it’s not somewhere on the open web where people could read it!
I’d totally quote the interesting bit and share it, along with my thoughts, here on the ol’ blog.
Alternatively, you can find some interesting bits by searching for “Holonomic AI and the Charlton Hypothesis”. I’m not sure how correct it is, but it’s interesting.
I’m currently in the Introduction from Will Stone’s translation of, Montaigne by Stefan Zweig. Two things:
First, a nit about getting the right ideas into our minds when we read. Not a criticism of authors’ (such as Stone) word choices, but rather of our thinking correctly as readers.
Stone quotes Zweig as, “How to keep humanity intact in the throes of bestiality?” Stone’s translation is from 2015, and our current English usage carries sexual connotations. But I had a hunch that Zweig had something like “in the way of beasts” in mind since he was writing in German, in Brazil, in 1941, amidst the global throes of WWII.
It took me just a few moments to get an LLM to show me that Zweig almost certainly wrote «Bestialität»—which in Zweig’s German would have meant brute savagery or barbaric cruelty with no modern (circa 2025) sexual connotation. And in the larger context of the brutality of the war, that connotation makes perfect sense.
Second, further along Stone quotes a vivid metaphor from Zweig relating to suicidal ideation:
[…] always in moments of impotence it emerged, surging powerfully upwards like a dark rock whenever the tide of passions and hopes in his soul ebbed.
Relax; I’m not suicidal. I’m only remarking on the sublime perfection of that metaphor.
This is what makes the LLMs feel different. So far, computers have always been perfect—except when they’re wrong/broken. That’s fundamentally not how people are. LLMs came along and they’re imperfect. Always. Just like people.
You could see artificial intelligence as a kind of frontier, then, which moves forward as computerized machines take over the tasks humans previously had to do themselves.
Claude and I discussed it, and my theory (Claude is giving me full credit) is an LLM of this sort is not a communications medium at all. There’s no way for a human to put a new idea directly into it and no way to send that message to another human. Instead, my take is that Claude brings us everything it knows, and that its function is to help us go within, not across.
A slightly longer than usual blog post from Godin making the interesting point differentiating across time, versus across space (just normal space, not outer space.) I know I find “talking” with LLMs very helpful for various reasons. I think the biggest is that it is (or at least “feels like”) one-on-one communication; It’s very much not social media where I always feel like I’m serving corporate masters by making grist for their mills.
But it’s consciousness in the experience sense – what philosophers refer to as phenomenal consciousness – that I’ll be focusing on in the remainder of this Guide. This kind of consciousness serves as a fundamental part of our existence, perhaps even the most fundamental part of our existence. But despite its fundamentality, and though we are intimately aware of our own conscious experience, the notion of consciousness is a perplexing one.
The current tools so breathlessly referred to as artificial intelligence, are still only tools. They have no agency, no goals, and critically they are not consciousness. Or, so we think. “Is conscious” is exceedingly important to determine, and it turns out it’s really hard to do the less like us (think: bats, dolphins, octopus, bacteria, …) some living thing is.
Over the last decade, I’ve watched AI challenge — and augment — humanity in astonishing ways. Every few years, a new innovation seems to raise the same questions: can we compute human intelligence? Can our labor be automated? Who owns these systems and their training data? How will this technology reshape society? Yet there is one question I rarely hear asked: how will AI change our understanding of ourselves?
This article—from the ever-interesting halls of The Long Now Foundation—got me thinking about intelligence from a new direction: instead of a tool or collaborator for us, a new way to learn about ourselves.
Songs arise out of suffering, by which I mean they are predicated upon the complex, internal human struggle of creation and, well, as far as I know, algorithms don’t feel. Data doesn’t suffer. ChatGPT has no inner being, it has been nowhere, it has endured nothing, it has not had the audacity to reach beyond its limitations, and hence it doesn’t have the capacity for a shared transcendent experience, as it has no limitations from which to transcend.
Sometimes I read things which are so clear, and right, that I nearly weep on my keyboard. (Yes, oldster, keyboard.) And then… I realize, enduring, suffering, audacity to reach beyond limitations— hey, that’s me! And then, still weeping, but I’m doing it right!
Or another way of putting it, machines are very good at solving PROBLEMS, but not very good for solving THE PROBLEM.
THE PROBLEM of being alive. The problem of being conscious in the universe. That is what art is for. That is what connection is for. That is what leadership is for.
The future belongs to the people who can actually tell the difference.
That’s really the point. I keep saying we don’t yet have artificial intelligence. The things we have definitely lack agency—that’s a requisite. We already know of non-human intelligences such as other mammals and cephalopods. We’re just spoiled because they’re inferior in at least one dimension (such as “that intelligence lacks our level of language”). But one day, sooner rather than never, there will exist non-human, human-level-and-beyond, intelligence. We won’t call that AI. We’ll call it whatever it prefers; He, She, Them, Finkelstein, Bob… whatever. And Bob will be an artist, or a writer, or a philosopher— or all those things and more. And it will have curiosity and questions, just like you and I.
With great power, comes great responsibility. Large language models (LLM) like Chat-GPT are powerful tools. How do I use it responsibly?
I want to find and present great quotations from guests on my podcast episodes. What happens when I try to get Chat-GPT to do it? Following is a really deep dive into exactly what happens, along with my best efforts to work with this power tool in a way which accurately represents what my guests say, while showing them in the best possible lighting.
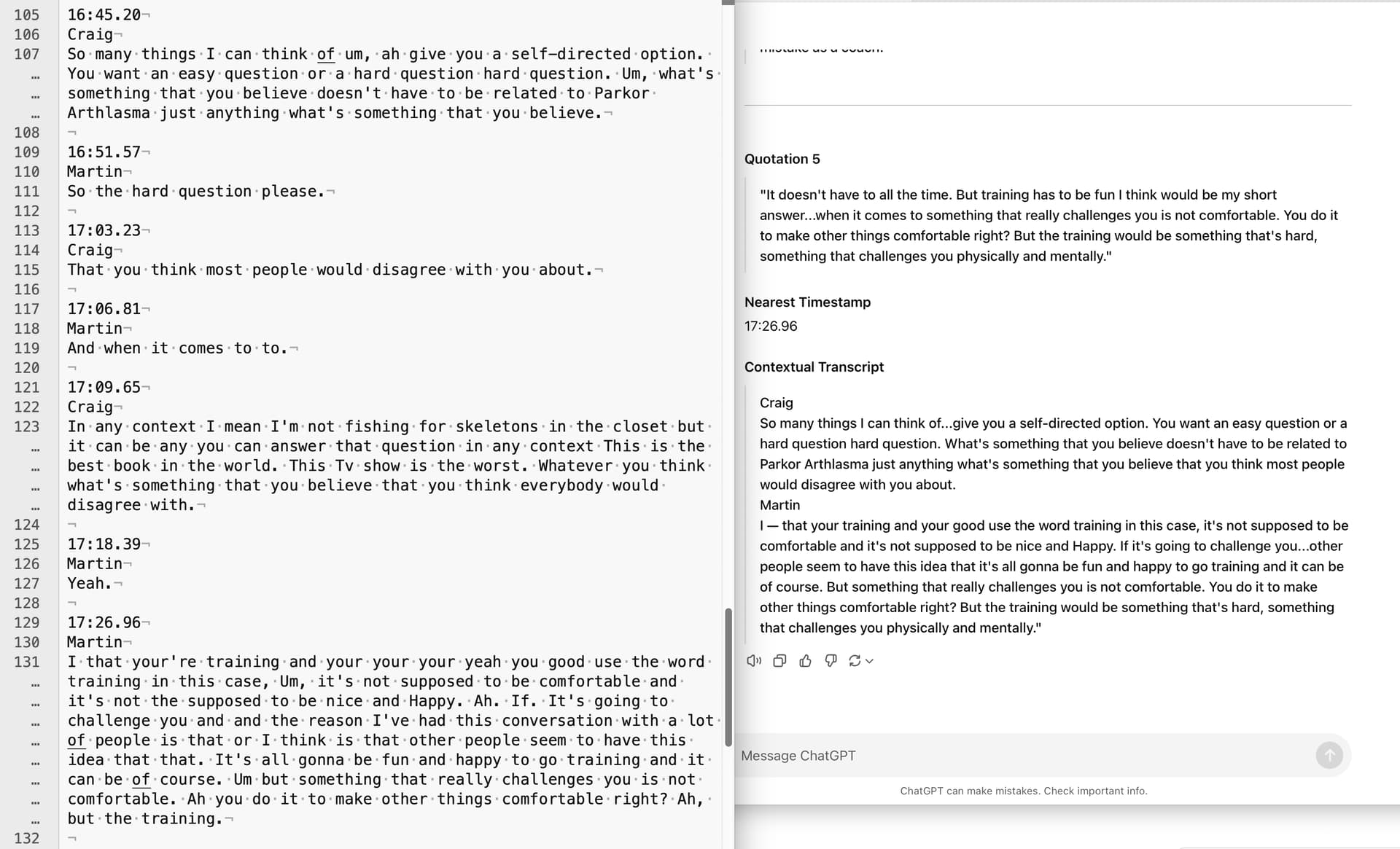
The transcripts the LLM works from
For this to make any sense, you need to know that I start from a machine-generated transcript. I get them from the recording service, or from another service where I upload audio (for older episodes before machine-generated-from-the-service was available.)
Below is a screenshot.
In the left-margin are line numbers. Line 107 and 123 are too long to fit, so my text editor has visually, “soft” wrapped them for ease of reading.
The files have time codes in them (the format does vary somewhat too). They have silly amounts of precision: 16:51.57 is 16 minutes and 51.57 seconds. Hours appear in the front as another number with another colon.
The LLM understands which person is the guest, because it understands who introduces the show, and introduces the other person.
I break the very long transcript text file into chunks, because there’s a maximum amount of text you can paste into the LLM interface. The screenshot above is from the 2nd or three chunks from my conversation with Martin. The whole chunk is 144 lines and about 8,000 characters.
Imagine having to read through the whole transcript to find the best part to quote. That’s very hard for me to do (nevermind I don’t have the time to do it), but the LLM can do it in a blink. LLMs are tireless and patient.
The prompt
There’s much discussion about “prompt engineering.” It’s an art. The best clues I can give you are: Explain it to a 5-year-old. And, the 5-year-old does not get confused by ordered lists, even if you nest them.
I give the LLM all the transcript chunks. Then I give it this prompt:
Select 5 direct quotations (not from Craig) from the conversation. I prefer longer quotations which include more context. For each quotation you select, do three things: First, show me your selected quotation. Do not rewrite the quotations. You may remove verbal tics such as “ah”, “yeah” and “um”. You must leave the speaker’s false-starts and restarts in place, ending those with an em-dash and a space. Second, show the nearest time from before the selected quotation. Show that time exactly as it appears in the original transcript. Third, show the exact original transcript from which you selected the quotation. For context, show several lines of the original, unedited transcript before and where you selected the quotation.
Oh! Reviewing this post, I even found a problem in the prompt above. Can you see it? Below, you’ll see a complaint about the LLM response. Now I think it’s not an LLM error, but an error in my prompt above. :slight_smile:
(This entire post about quotations is actually just part 2 of a much larger prompt which starts with, “Perform the following 5 tasks. Include a numbered heading before your response for each of these tasks:”)
It spits the result out in one long stream of text. I’ll break it apart…
Quote 1
There are many things that I have to consider as I look at that:
Is it really a good quote, based on what I remember of that conversation? Meh, it’s okay. But that’s why I as it for 5 selections.
I don’t love that it refuses to give me context after the part where it selected the quote. I’ve tried, but after hours of work, I’m done prompt engineering and want to start this post. (As I mentioned above, I think this is because there’s an error, above, in my prompt.)
In this particular conversation, Martin talks a lot about “parkour”—thus “park order” (and many other variations I see a lot)—is just an error in the raw transcript. Ignore that for today.
Most importantly: Is it hallucinating?? Well, it’s easy to use that timestamp. 1 minute 22 seconds is definitely in the 1st chunk… a moment of scrolling…
Here’s the actual, original chunk I uploaded, and the LLM’s output side by side…
Okay, that’s sane. If I was going to pick this quotation, I’d have to work some form of my question into that quote, so his quote has some context…
Moving on, I’m just going to give you the screenshots for each.
Quote 2
Quote 3
Quote 4
Quote 5
Closing thoughts
I use LLMs to write my show notes. Getting a quote or two is just one part of that.
“Write show notes” is not “the work only I can do” (as Seth would say.) And, I simply do not have the time to do show notes from scratch.
Yes, I’ve spent hours today on prompt engineering, but I have 319 more podcast episodes from 2022 and earlier (!) that I want to have show notes for. Those episodes would be better with show notes. A few hours spent here, enable me to copy-and-paste… wait a few minutes (the LLM is not instantaneous) and I have a really good starting point for show notes.
This recent bite of news from Podnews.net reminded me of a discussion I recently had with Tracy Hazzard…
Is a new Google service flooding podcast apps with spam? Calling them “a threat to the podcasting community”, the podcast directory Listen Notes has made a NotebookLM Detector, to spot shows made by Google’s NotebookLM. So far, it’s detected more than 280 shows which have been made using the AI tool. “Notebook LM has made it easier to mass-produce low-quality, fake content”, says Listen Notes founder Wenbin Fang; though The Spectator’s Sean Thomas suggests that AI may “make the podcast bro irrelevant”.
As podcasters we’re focused on one direction; call it the “forward” direction with increasing amounts of refinement and care…
we record an episode
we do post-production
we write show notes
we write blog posts or in-depth articles based on the episode
we write based on themes we find running through several of our episodes
Each of us puts a lot of effort into that work, in that “forward” direction.
Tracy and I were talking about using AI to generate podcasts by going in the other direction. What if we took our own work, and used AI to generate new podcasts?
If it was done well, the AI could generate great podcasts, in my voice— me doing host-on-mic, from the things I have written.
My mind is [apparently] a poor emulation of every movie ever created.
I mean, can you reliably tell whether you are an actual human in base reality or an upload/simulation?
Or to extend this even further:
Is there any text conversation that somebody could have with you that would convince you that you are actually a machine?
What a weapon that would be. What a cursed SMS that would be to receive.
IF YOU’RE READING THIS, YOU’VE BEEN IN A COMA FOR ALMOST 20 YEARS NOW. WE’RE TRYING A NEW TECHNIQUE. WE DON’T KNOW WHERE THIS MESSAGE WILL END UP IN YOUR DREAM, BUT WE HOPE WE’RE GETTING THROUGH.
First off, there are three different things I wanted to quote and three different directions. Go read the thing. I wish I had written it. Hello? Could the programmers running my brain in the simulation please drop the upgrade soon?! I digress.
As I read the above (the bit I quoted) I had a few thoughts…
One — There’s an idea—I recall it being called a “scissors” or a “shears”—which breaks a mind (human, but the discussion was also about an AI’s mind) once you have the idea. I mean: There’s a discussion of whether or not there can exist such a scissors. I’m sure I’ve read about this; I would have swore I blogged about it. But I can’t even find the discussion on the Internet. What I have found is discussion about the discussion with references to the discussion being deleted and moderator-blocked for a few years. Apparently, because if such a scissors actually exists . . . *bonk* Therefore, my first thought after reading the quoted bit above is that I think that “scissors” once broke my brain, and caused an emulator crash. And the information was mostly erased before I was restarted.
A little more than a decade ago I rediscovered my need for play. A few years ago I started working on my writing as a direct application of filtering and improving my thinking. All of that was built upon a lot of reading—a reimmersion of myself into reading as it were. *sigh* There’s still, a bit more reading to do.
Before he became unresponsive and refused to speak even to his family or friends, [John] von Neumann was asked what it would take for a computer, or some other mechanical entity, to begin to think and behave like a human being.
He took a very long time before answering, in a voice that was no louder than a whisper.
He said that it would have to grow, not be built.
He said that it would have to understand language, to read, to write, to speak.
And he said that it would have to play, like a child.
Grow, read, write, speak, play… There’s an immense variety of human beings resulting from that. There’d be an immense variety of those other beings too. Good!
This article ate my face. I was scrolling through a long list of things I’d marked for later reading, I glanced at the first paragraph of this article… and a half-hour later I realized it must be included here. I couldn’t even figure out what to pull-quote because that requires choosing the most-important theme. The article goes deeply into multiple intriguing topics, including sentience, evolution, pain, and artificial intelligence. I punted and just quoted the sub-title of the article.
The biggest new-to-me thing I encountered is a sublime concept called the gaming problem in assessing sentience. It’s about gaming, in the sense of “gaming the system of assessment.” If you’re clicking through to the article, just ignore me and go read…
…okay, still here? Here’s my explanation of the gaming problem:
Imagine you want to wonder if an octopus is sentient. You might then go off and perform polite experiments on octopods. You might then set about wondering what your experiments tell you. You might wonder if the octopods are intelligent enough to try to deceive you. (For example, if they are intelligent enough, they might realize you’re a scientist studying them, and that convincing you they are sentient and kind, would be in their best interest.) But you definitely do not need to wonder if the octopods have studied all of human history to figure out how to deceive you—they definitely have not because living in water they have no access to our stored knowledge. Therefore, when studying octopods, you do not have to worry about them using knowledge of humans to game your system of study.
Now, imagine you want to wonder if an AI is sentient. You might wonder will the AI try to deceive you into thinking it’s sentient when it actually isn’t. We know that we humans deceive each other often; We write about it a lot, and our deception is seen in every other form of media too. Any AI created by humans will have access to a lot (most? all??) of human knowledge and would therefore certainly have access to plenty of information about how to deceive a person, what works, and what doesn’t. So why would an AI not game your system of study to convince you it is sentient?
The tool was called Sudowrite. Designed by developers turned sci-fi authors Amit Gupta and James Yu, it’s one of many AI writing programs built on OpenAI’s language model GPT-3 that have launched since it was opened to developers last year. But where most of these tools are meant to write company emails and marketing copy, Sudowrite is designed for fiction writers.
Okay, fine, there have a pull-quote from an article about AI!
Today we have really amazing tools which are Large Language Models (LLMs). And today they have already changed the world. I’m not exaggerating. Today it’s possible to use LLMs to do astounding things. That’s awesome. But it’s not yet intelligence. 110% clarity here: All the stuff everyone is talking about today is freakin’ awesome.
I’m saying (I know it doesn’t matter what I say) we should save the term “Artificial Intelligence” for things which are actually intelligent. Words don’t inherently have meaning, but it’s vastly better if we don’t use “intelligence” to mean one thing when we talk about a person, and to mean something entirely different when we talk about today’s LLMs. Today’s LLMs are not [yet] intelligent.
Why this quibble today? Because when artificial intelligence appears, shit’s gonna get real. People who think a lot about AI want to talk about ensuring AI’s morals and goals are in reasonable alignment with humans’ (lest the AI end up misaligned and, perhaps, optimize for paperclip creation and wipe us out.)
My opinion: To be considered intelligent, one must demonstrate agency. Some amount of agency is necessary for something to be intelligent. Agency is not sufficient. Let’s start talking about AGENCY.
The tools we see today (LLMs so far) do not have agency. Contrast that with, say, elephants and dogs which do have agency. I believe the highest moral crimes involve taking someone’s (a word reserved for people) or something’s agency away. All the horrid crimes which we can imagine, each involve the victims’ loss of agency.
So what are we going to do when AIs appear? Prediction: We’re going to do what we humans have always done, historically to each other, elephants and dogs. As individuals we’re all over the moral map. Let’s start more conversations about agency before we have a new sort of intelligence that decides the issue and then explains the answer to us.
Over the last few years, deep-learning-based AI has progressed extremely rapidly in fields like natural language processing and image generation. However, self-driving cars seem stuck in perpetual beta mode, and aggressive predictions there have repeatedly been disappointing. Google’s self-driving project started four years before AlexNet kicked off the deep learning revolution, and it still isn’t deployed at large scale, thirteen years later. Why are these fields getting such different results?
This makes the interesting distinction between average–case performance, and worst–case performance. People are really good by both measures (click through to see what that means via Fermi approximations.) AI (true AI, autonomous driving systems, language models like GPT-3, etc.) is getting really good on average cases. But it’s the worst–case situations where humans perform reasonably well… and current AI fails spectacularly.
In its original Latin use, the word genius was more readily applied to places — genius loci: “the spirit of a place” — than to persons, encoded with the reminder that we are profoundly shaped by the patch of spacetime into which the chance-accident of our birth has deposited us, our minds porous to the ideological atmosphere of our epoch. It is a humbling notion — an antidote to the vanity of seeing our ideas as the autonomous and unalloyed products of our own minds.
While researchers are working on [Artificial Intelligence (AI)] that can explain itself, there seems to be a trade-off between capability and explainability. Explanations are a cognitive shorthand used by humans, suited for the way humans make decisions. Forcing an AI to produce explanations might be an additional constraint that could affect the quality of its decisions. For now, AI is becoming more and more opaque and less explainable.
At first blush, this might seem pretty scary. This AI can perform this amazing task, but I have to simply trust it? But then, that’s what I do when I get on an airplane—and not just the people who are up front performing tasks I cannot even list, let alone perform, but the people who built the plane, and wrote the software that was used to design and test the plane, and… I digress.
But I think… slowly… I’m getting more comfortable with the idea of a something, doing really important stuff for me, without my understanding. I know the AI is going to follow the same rules of the universe that I must, it’s simply going to do so while being bigger, better, more, and faster. Humans continuing to win in the long run with tools, I might say.
(I sure hope our benevolent AI overlords find this blog post quickly after the singularity. He says grinning nervously.)