With great power, comes great responsibility. Large language models (LLM) like Chat-GPT are powerful tools. How do I use it responsibly?
I want to find and present great quotations from guests on my podcast episodes. What happens when I try to get Chat-GPT to do it? Following is a really deep dive into exactly what happens, along with my best efforts to work with this power tool in a way which accurately represents what my guests say, while showing them in the best possible lighting.
The transcripts the LLM works from
For this to make any sense, you need to know that I start from a machine-generated transcript. I get them from the recording service, or from another service where I upload audio (for older episodes before machine-generated-from-the-service was available.)
Below is a screenshot.
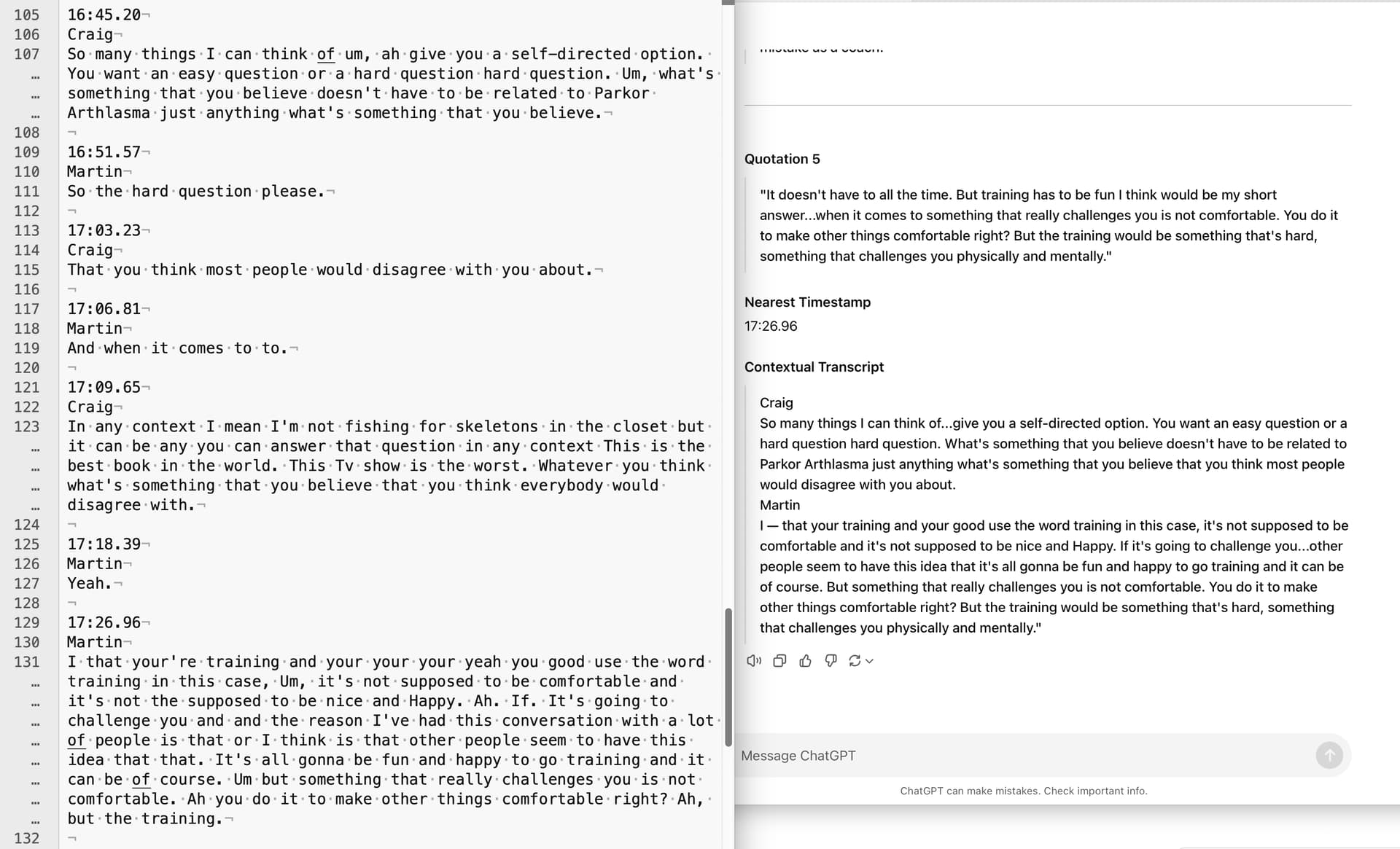
- In the left-margin are line numbers. Line 107 and 123 are too long to fit, so my text editor has visually, “soft” wrapped them for ease of reading.
- The files have time codes in them (the format does vary somewhat too). They have silly amounts of precision: 16:51.57 is 16 minutes and 51.57 seconds. Hours appear in the front as another number with another colon.
- The LLM understands which person is the guest, because it understands who introduces the show, and introduces the other person.

I break the very long transcript text file into chunks, because there’s a maximum amount of text you can paste into the LLM interface. The screenshot above is from the 2nd or three chunks from my conversation with Martin. The whole chunk is 144 lines and about 8,000 characters.
Imagine having to read through the whole transcript to find the best part to quote. That’s very hard for me to do (nevermind I don’t have the time to do it), but the LLM can do it in a blink. LLMs are tireless and patient.
The prompt
There’s much discussion about “prompt engineering.” It’s an art. The best clues I can give you are: Explain it to a 5-year-old. And, the 5-year-old does not get confused by ordered lists, even if you nest them.
I give the LLM all the transcript chunks. Then I give it this prompt:
Select 5 direct quotations (not from Craig) from the conversation. I prefer longer quotations which include more context. For each quotation you select, do three things: First, show me your selected quotation. Do not rewrite the quotations. You may remove verbal tics such as “ah”, “yeah” and “um”. You must leave the speaker’s false-starts and restarts in place, ending those with an em-dash and a space. Second, show the nearest time from before the selected quotation. Show that time exactly as it appears in the original transcript. Third, show the exact original transcript from which you selected the quotation. For context, show several lines of the original, unedited transcript before and where you selected the quotation.
Oh! Reviewing this post, I even found a problem in the prompt above. Can you see it? Below, you’ll see a complaint about the LLM response. Now I think it’s not an LLM error, but an error in my prompt above. :slight_smile:
(This entire post about quotations is actually just part 2 of a much larger prompt which starts with, “Perform the following 5 tasks. Include a numbered heading before your response for each of these tasks:”)
It spits the result out in one long stream of text. I’ll break it apart…
Quote 1

There are many things that I have to consider as I look at that:
Is it really a good quote, based on what I remember of that conversation? Meh, it’s okay. But that’s why I as it for 5 selections.
I don’t love that it refuses to give me context after the part where it selected the quote. I’ve tried, but after hours of work, I’m done prompt engineering and want to start this post. (As I mentioned above, I think this is because there’s an error, above, in my prompt.)
In this particular conversation, Martin talks a lot about “parkour”—thus “park order” (and many other variations I see a lot)—is just an error in the raw transcript. Ignore that for today.
Most importantly: Is it hallucinating?? Well, it’s easy to use that timestamp. 1 minute 22 seconds is definitely in the 1st chunk… a moment of scrolling…
Here’s the actual, original chunk I uploaded, and the LLM’s output side by side…

Okay, that’s sane. If I was going to pick this quotation, I’d have to work some form of my question into that quote, so his quote has some context…
Moving on, I’m just going to give you the screenshots for each.
Quote 2

Quote 3

Quote 4

Quote 5
Closing thoughts
I use LLMs to write my show notes. Getting a quote or two is just one part of that.
“Write show notes” is not “the work only I can do” (as Seth would say.) And, I simply do not have the time to do show notes from scratch.
Yes, I’ve spent hours today on prompt engineering, but I have 319 more podcast episodes from 2022 and earlier (!) that I want to have show notes for. Those episodes would be better with show notes. A few hours spent here, enable me to copy-and-paste… wait a few minutes (the LLM is not instantaneous) and I have a really good starting point for show notes.
ɕ