This article got out of hand, and is 3,000 words. I encourage you to skip around; There’s more discussion of specific tools and how-to material in the last third.
In the beginning
In the beginning, podcasts were simply audio files which people shared directly either by emailing them to each other, or by providing download links on their web sites.
RSS technology has been around for a while and provided a way for a web site to publish a “here’s what’s new” feed. It was soon realized that RSS could be used to provide a feed specifically of podcasts. Software able to retrieve and understand a podcast feed, could then automatically download the podcast files, and alert you of new episodes. Sharing a new show with friends then meant simply giving them the “feed URL” which one would “subscribe to” by adding it to your feed reader.
It was only a matter of time before someone realized that a central directory that stored all the feed URLs would be extremely useful. That directory would enable me to search for new shows, new episodes (across any show), and so on.
All of this depends on meta-data; information about the shows and about each episode. Applications for mobile platforms, desktops, and web sites sprang up each of which communicated only with some directory. At first, it was just Apple’s iTunes directory of podcasts, but now there are many different directories maintained by various entities.
Today, “submitting” your show means getting it added to a directory.
About the feeds
A feed contains two things: Information about the podcast (name, author, description, etc.) and a list of episodes and their information (title, description, download URL for the audio file, etc.). Specifically, it’s a file marked-up with XML which is meant to be read by programs. Here’s a screenshot of a podcast feed shown as raw text:

Here’s the same feed shown using a tool which understand the XML and can present it in a way slightly easier for humans to read:

Ignore those yellow highlights as it’s just commentary from the parser. Note that the display goes for more than 1,600 lines.
No one creates these feeds by hand. They need to change frequently, (each time an episode is published,) and it’s tedious. So show feeds are generated automatically. This is why you “publish” your show in one place, and then you have to “submit” your show to the directories, but then you can publish new episodes without having to notify anyone/anything.
You can install software on your web site which will let you create your episodes and it will generate your feed from there. That software would tell you the URL where it created your feed. You can join a service which lets you upload your episodes, and type in some of the meta-data. The service will then handle playing the file to people who use their web site or mobile app, and it will, (perhaps,) generate a feed for you too. In both these cases you can take your feed URL and submit it to other directories. (I’ll talk more about how this leads an ecosystem, below.)
The key take-away here is: Some software or service is creating your podcast feed (the “publisher”) and some service(s) are consuming your podcast feed (the “directories.”)
The publishers—whether this is your own WordPress web site with Podcast publishing plugins, or service like Simple Cast—accept your episodes when you upload them, take the meta-data you enter (title, description) and create your feed. The directories accept your show’s initial registration and then continuously consume all of the feeds from all show publishers, building a database of all known shows and episodes.
Potential problem: Detecting updated feeds
Directories have a big challenge: If there are +500,000 shows, by definition that means there are that many feed URLs. People want to see episodes appear immediately. The directory has to monitor those half-million URLs for changes. How often does it “poll” each URL?
After over a decade, things are quite advanced. Directories can ask, “is it updated?” instead of “give me the whole thing” and checking against their last fetched data. They can also learn how often each show generally publishes, and then adjust their checking to better align with that. But this is still a HUGE number of requests they need to make.
On the other side, where your feed is published, do you really want each directory (there are dozens) asking your publishing service, “is it updated?” “is it updated?” every five minutes?
This is simply an effect of the nature of RSS feeds; They are “pulled” by the consumer. The solution, created long ago, is to create a push-pull system, (I prefer to call it “bump-pull.”) The publishing service, (WordPress, Simple Cast, etc.,) sends a small alert to a hub whenever the podcast feed is updated. The directories subscribe to podcast feeds by telling the hub, “notify me if this feed URL notifies you.”
Now the directories can vastly cut down their workload. They immediately fetch any RSS feed when the hub bumps them to inform that the publisher bumped them. They can also look for stale feeds which haven’t been updated recently and proactively make a direct request to the feed publisher, “hello? is this thing still on?” and see what they get back.
This started as a proprietary project and has become an open standard, WebSub. James Cridland of Podnews.net has written an excellent article, A Podcast Industry Guide to WebSub, or PubSubHubbub.
Ecosystem
Having covered the publishers, and the directories, the last part is the players (the software which plays the audio files.) Your favorite podcast player has three parts:
- A searching and subscribing front end that enables you to find things in somedirectory,
- a download-and-store or streaming (or both) manager for the podcast files,
- and an audio player. (…hey look, finally! …this is the entire point of podcasting!)
This creates a beautiful ecosystem where the publishing services do their job creating standardized feeds, and serving out the podcast audio files when they are downloaded or streamed-live. The directories create large databases of what shows and episodes exist, their titles, their content ratings, where’s the episode cover art, etc. The players (mobile apps, desktop apps, and web sites) handle all the end-user interface features (playback speed, silence-skipping, rewind, subscribe, sharing, episode play ordering, auto-download for offline listening, and on and on.)
Potential problem: Who pays for this?
I don’t believe our species can survive unless we fix this. We cannot have a society, in which, if two people wish to communicate, the only way that can happen is if it’s financed by a third person who wishes to manipulate them.
~ Jaron Lanier
Publishing: My personal soapbox is that the podcast creator must choose to pay for the publishing part of the ecosystem. There are a few ways to do this, from choosing a partner which charges to create your feed, to rolling your own from scratch with a hosting company. It’s a good sign that there are a huge number of ways to “publish” your podcast; This part of the ecosystem is doing very well.
Listening: For your podcast player, you should always choose one which is notfree; It’s best if it’s one which charges a recurring fee, (annual is nice,) to the software provider to support their work. Never use free-with-ads players, unless you can pay to remove the ads (and you should do so to support that project.) This part of the ecosystem is doing mediocre.
Directories: Unfortunately, the directories you can’t actually pay. Some of the publishers are their own directory, which they use to enable only their own players. So in some cases you are effectively supporting a directory through your choice of publisher. That may or may not be a good thing.
Fracturing of the ecosystem
Suppose I want to listen to a show. (My friend said I should listen to, “Movers Mindset.”) I open my favorite player and search, but I can’t find it. What do I do? Well, as the end-listener, I can do nothing. As a show creator you are going to find this endlessly frustrating.
What’s going on is that some entities want to control the listeners (the people using the players,) so they entice podcast creators to submit their show feed to their closed directory. There are many of these closed directories. Even worse, they always come with odious click-wrap contracts; To submit your show, you have to agree that they can alter it by adding ads, or that you must defend them in court cases, and so on.
Apple’s iTunes directory is currently the only open directory; Meaning anyone can create player-software that uses their directory. Creating a player is not easy, and there are rules from Apple about directory use, but it is open to anyone’s use. There are other open directories, but they don’t have nearly as many shows as Apple’s, yet.
Currently (spring 2019) the BBC is embroiled in a PR mess for having removed all of their shows from Google’s podcasts directory. (Google’s podcast directory is not open, but Googles player apps use it, and that’s a lot of listeners.) The BBC wants people to use the BBC-provided players. But the rest of the podcast universe is not in the BBC’s directory, and so not available in their player. That means I have to have two players: one for the BBC and one for all the other plays-well-with-others podcast shows. In reality, I feel it’s best to simply shun any shows which refuse to be good podcast citizens and feed into the public directories.
On the other hand, it is not a good idea to have one single entity stewarding the only open directory that is large enough to be useful. We’re all currently relying on Apple to remain the adult in the room as the caretaker of the directory. I don’t like this idea either. Switching our lone egg to another basket controlled by someone else is no better.
What we, the podcast creators need is a self-assembled directory that we all co-create and take part in supporting. It would be built by the creators, and run by funding from the creators. This would become the One True Directory. Each show would pay a small annual fee to register in the global directory. This may sound familiar. Solving the problem of who controls the domain names on the Internet is the same problem of cooperation. The U.S. government started the domain name system, and some wise people worked really hard to create and shift everything to a global entity which now controls it democratically.
Potential problem: How many episodes can a show have?
The answer would seem to be “as many as the creator wants” but there’s a potential problem with the podcast feed structure. How many episodes are actually included in the feed? Directories do not store episodes’ information if they disappear from a feed; You wouldn’t be able to delete an episode if they did that. (Well, not easily, and not without some changes to how RSS works.)
The directories just keep the information which is currently in each feed. If the feed has 12 items, (some real-world defaults are this low,) when you publish episode 13, episode 1 “falls off” the bottom of your feed. This makes it disappear from the directories and from the players. (Cue your friends saying, “I can’t find that episode in my player.”)
If you want every episode of your show to remain in the directory, and therefore findable and playable, you need to ensure the feed will include that many episodes.
Here’s where it starts to be clear why you might want to control your own publishing deployment. What if your chosen publisher only includes 25 episodes? (More realistically, the free version of their publishing service limits you to a very small number to encourage you to step up.) If you have control of your podcast feed publication you can always change anything. The downside of course is the need for the technical knowledge to operate and publish the feed.
How to examine your feed
There are many web sites that will validate XML. (Remember, your show’s feed is marked up with XML.) A great example, which has been around as long as I can remember, is from the World Wide Web Consortium (W3C). Their XML validator is https://validator.w3.org/feed/ and here’s what is has to say about the Movers Mindset feed:

That’s rather gnarly looking. But it is also very accurate. If it mattered, I would change the feed to fix every one of those problems it reports. As it turns out though, the directories are not so strict when it comes to reading these feeds.
What we really need is an XML validator that understand we are trying to verify our podcast feed. Turns out this is also a thing. Meet your new best friend, the Cast Feed Validator. Here’s what it has to say about the Movers Mindset feed:

(Go find your feed URL and put it into the Cast Feed Validator.)
This is much easier to understand. The Cast Feed Validator is doing two jobs: Checking the structure of our feed (the XML validation) and checking for “podcast sanity.” It does a beautiful job of visually presenting the information in a way that we can see what’s going on, without having to directly read the XML ourselves.
We can take this a step further. Podnews.net runs a free lookup service which checks a lot of things about your feed—not the feed XML validity per se. I call this “meta-commentary” as they will tell you which directories you are visible in, and other nuances such as wether you are doing your titles in a way that makes Apple happy. The Movers Mindset page from Podnews’ includes a lot (not shown here) but this section is priceless:
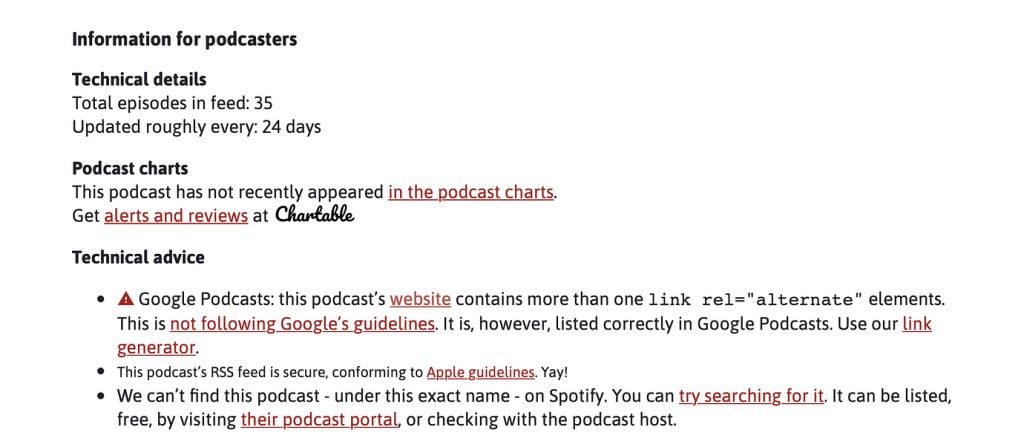
Troubleshooting Wizardry
One day, something is wrong… is it with the publisher of your show’s feed, the directory, or the player?
First off, I’d like to point out that since you are now able to understand how those three interact, you are way ahead on problem solving. You’ll know to ask questions to start teasing out, (from whoever reported the problem,) in which of the three parts of the ecosystem does the problem lie. “What player are you using?” is something you will grow tired of asking.
The vast majority of problems I have encountered, (or heard of,) fall into two categories:
- the directory doesn’t include the feed at all, or it hasn’t fetched the feed recently
- the information in the feed is wrong, mangled, missing, etc.
The first problem is mostly beyond the control of the podcast creator. We can submit our show’s feed URL, and we can reach out to support if it’s not yet included. But generally, directories poll for changes as they see fit and you’re either in, or you’re out. However, “I can’t find it in my player,” is almost alwaysbecause your show isn’t in the corresponding directory. This isn’t really a problem. It’s really just expected behavior.
The second case is where all the problems fall.
But first, I want to show you one more tool that will take you to Wizard-level.
Saving a copy of your feed to a text file
If you can save your podcast feed to a file, then you can do “before and after” comparisons. Imagine you find a problem and you think you’ve fixed it. (Perhaps you’ve made a change in your publishing service’s web interface; maybe you want to change all your episode titles to conform to Apple’s latest rules.)
Unfortunately, I cannot provide specific instructions because there are so many environments. But if you can figure out how to save your feed from your web browser—point your browser at your podcast feed, what happens? …can you save-as… to capture it? Or, if you know how to use a command-line on your computer, do you have the “curl” program installed? And so on…
I know I’m way out in the weeds here, but here’s a screenshot from a tool for showing the differences between two files. In this case, I saved a copy of the feed before and after making some text change. (I edited the HTML tags in the sponsorship section of an older podcast.) I can quickly verify that the onlydifferences are what I wanted:
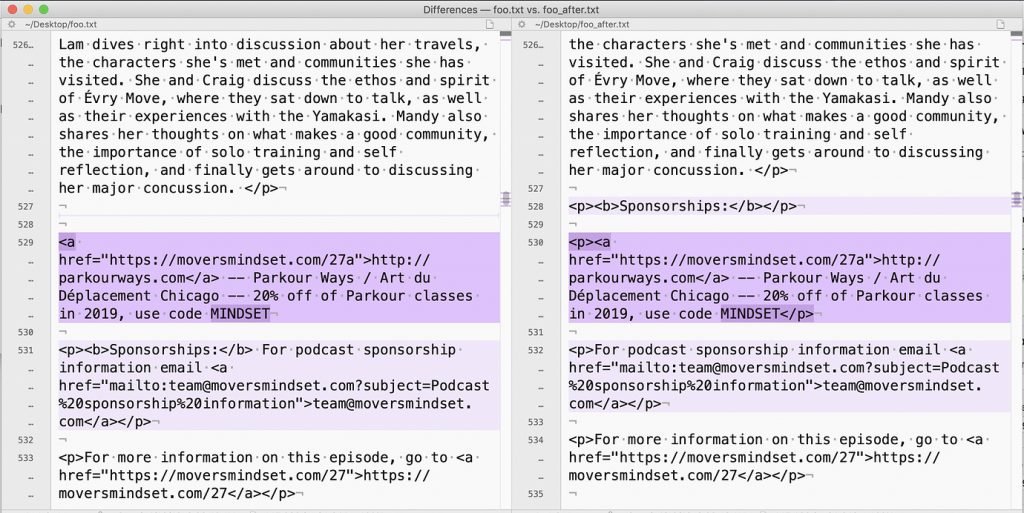
If I didn’t know how to do this with my feed, I’d have to wait for some directory to load the feed and then wait for my favorite player app to refresh… and then realize I have typo… arrrr! another day-delay… Instead, save a copy, make a change, verify the change, and I’m done.
Namespaces in XML
Wow, you’re still reading?
You may have noticed in the screenshots of XML, that some tags are, <title>and some have a colon in them like, <itunes:title>. The itunes: part is an XML namespace. This enables everyone to invent their own tags without having to all agree on the tag names. So Apple’s directory will use the <title>information, unless you specify an <itunes:title>—then they’ll prefer their tag. You’ll see this come up when you read things like, “if you use Apple’s tags, you can…”
There are lots of namespaces and they’re declared at the top of the XML files with xmlns:URL in the (in this case) main <rss ...> tag that begins the XML. Don’t bother learning them—even I’m not that crazy. Instead, just remember that namespaces are a thing that groups tags.
In early 2019 there was a lot of noise about Apple changing the rules about podcast tiles. Your first thought should be, “why does Apple make the rules?” …they don’t, they make rules about what their directory will accept. Technically, they always had the rule that caused the fuss. What happened was they emailed all the creators and said they were going to start enforcing it. The rules is that numbers—among many other things—are not allowed in titles. So, “23. Interview with John Doe” is not allowed as an episode title by Apple.
Everyone freaked out.
A few people noted the rule is actually: Numbers are not allowed in Apple’s title tag. Which means, not allowed in the title tag in Apple’s namespace, our friend the <itunes:title> tag. So I went in and fixed all my <itunes:title> tags. In the end this was an improvement to our feed overall. Now I have my general <title> tags with what I want, (we happen to use numbers as prefixes,) and I conform to Apple’s guidelines for their Apple-namespace titles.
Parting thoughts
Remember that feeds are meant to be read by the computers. You shouldn’t have to ever mess with any of this, but now that you know how…
I didn’t bother talking about the various tags in the feed file. Now that you have some tools, you’ll discover the tag names have obvious meanings.
ɕ